Sklearn Random Forest Classifier - Why Is Random Forest Better Than Decision Tree?

Sklearn random forest classifier
Random forest algorithm avoids and prevents overfitting by using multiple trees. The results are not accurate. This gives accurate and precise results. Decision trees require low computation, thus reducing time to implement and carrying low accuracy.
What is the difference between random forest and XGBoost?
Random Forest algorithm uses fully grown decision trees to classify possible emitter position, trying to achieve error mitigation by reducing variance. On the other hand, XGBoost approach uses weak learners, defined by high bias and low variance.
Is random forest better than logistic regression?
In general, logistic regression performs better when the number of noise variables is less than or equal to the number of explanatory variables and random forest has a higher true and false positive rate as the number of explanatory variables increases in a dataset.
What is the use of random forest classifier?
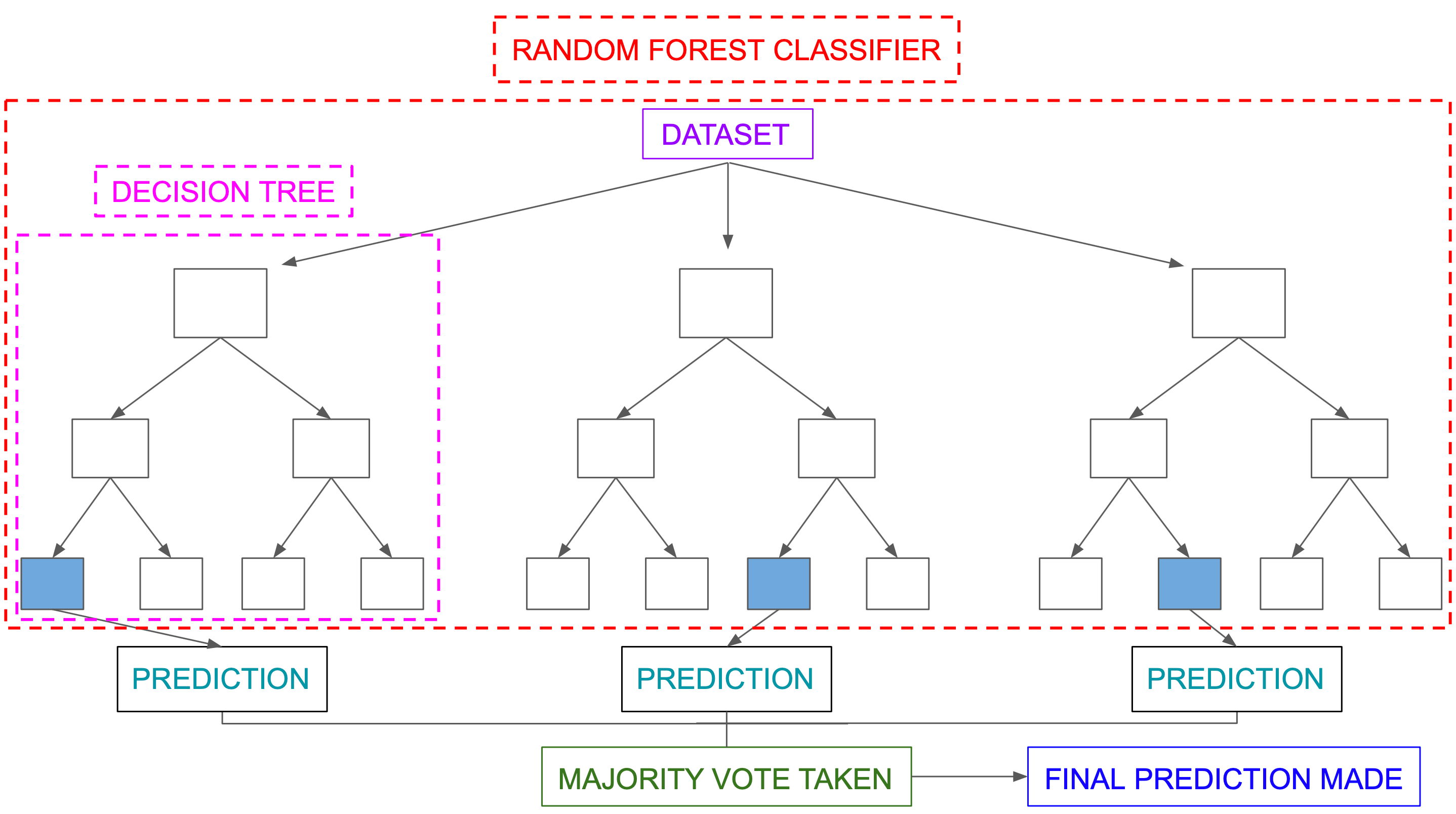
The Random forest classifier creates a set of decision trees from a randomly selected subset of the training set. It is basically a set of decision trees (DT) from a randomly selected subset of the training set and then It collects the votes from different decision trees to decide the final prediction.
What is the difference between decision tree and random forest?
A decision tree combines some decisions, whereas a random forest combines several decision trees. Thus, it is a long process, yet slow. Whereas, a decision tree is fast and operates easily on large data sets, especially the linear one. The random forest model needs rigorous training.
Is random forest supervised or unsupervised?
Random forest is a Supervised Machine Learning Algorithm that is used widely in Classification and Regression problems. It builds decision trees on different samples and takes their majority vote for classification and average in case of regression.
What causes overfitting in random forest?
We can clearly see that the Random Forest model is overfitting when the parameter value is very low (when parameter value < 100), but the model performance quickly rises up and rectifies the issue of overfitting (100 < parameter value < 400).
Do you need to scale data for random forest?
Stack Overflow: (1) No, scaling is not necessary for random forests, (2) Random Forest is a tree-based model and hence does not require feature scaling.
Can random forest predict continuous variable?
Can Random Forest be used both for Continuous and Categorical Target Variable? Yes, it can be used for both continuous and categorical target (dependent) variable.
What is a good max depth for random forest?
Generally, we go with a max depth of 3, 5, or 7. max_features: The number of columns that are shown to each decision tree. The specific features that are passed to each decision tree can vary between each decision tree.
Is random forest classification or regression?
Random Forest is an ensemble of unpruned classification or regression trees created by using bootstrap samples of the training data and random feature selection in tree induction. Prediction is made by aggregating (majority vote or averaging) the predictions of the ensemble.
What are the pros and cons of random forest?
Works well with non-linear data. Lower risk of overfitting. Runs efficiently on a large dataset. Better accuracy than other classification algorithms. ... Cons:
- Random forests are found to be biased while dealing with categorical variables.
- Slow Training.
- Not suitable for linear methods with a lot of sparse features.
Is random forest bagging or boosting?
The Random Forest model uses Bagging, where decision tree models with higher variance are present. It makes random feature selection to grow trees.
Can random forest handle categorical variables?
One advantage of decision tree based methods like random forests is their ability to natively handle categorical predictors without having to first transform them (e.g., by using feature engineering techniques).
What are the limitations of random forest classifier?
The main limitation of random forest is that a large number of trees can make the algorithm too slow and ineffective for real-time predictions. In general, these algorithms are fast to train, but quite slow to create predictions once they are trained.
Why is random forest better than boosting?
There are two differences to see the performance between random forest and the gradient boosting that is, the random forest can able to build each tree independently on the other hand gradient boosting can build one tree at a time so that the performance of the random forest is less as compared to the gradient boosting
How many trees should I use in random forest?
They suggest that a random forest should have a number of trees between 64 - 128 trees. With that, you should have a good balance between ROC AUC and processing time.
Can I use random forest for time series?
A random forest regression model can also be used for time series modelling and forecasting for achieving better results. Traditional time series forecasting models like ARIMA, SARIMA, and VAR are based on the regression procedure as these models need to handle the continuous variables.
How do I use random forest in Python?
Below is a step-by-step sample implementation of Random Forest Regression.
- Implementation:
- Step 1: Import the required libraries.
- Step 2: Import and print the dataset.
- Step 3: Select all rows and column 1 from dataset to x and all rows and column 2 as y.
- Step 4: Fit Random forest regressor to the dataset.
Can random forest handle imbalanced data?
Random forest is an ideal algorithm to deal with the extreme imbalance owing to two main reasons. Firstly, the ability to incorporate class weights into the random forest classifier makes it cost-sensitive; hence it penalizes misclassifying the minority class.
13 Sklearn random forest classifier Images
python How to real calculate random forest feature importance on

Workflowrandom forest classifier Download Scientific Diagram

Learn and Build Random Forest Algorithm Model in Python Intellipaat
sklearnensembleRandomForestRegressor scikitlearn 102 documentation

Framework of Random Forest classifier Download Scientific Diagram

Working procedure of Random Forest classifier Download Scientific

SKLearn 16 Random Forest Classification Hutan Acak Belajar
Random Forest Algorithm InsideAIML Article

Building Random Forest Classifier with Python scikitlearn Edit View

sklearn Random ForestDetailed Classification Parameters
Random Forest Classifier The Click Reader
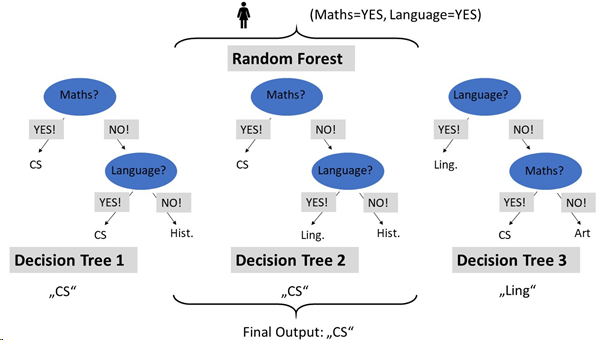
Random Forest Classifier Made Simple Finxter
Davvero 35 Fatti su Random Forest Classifier Example Fit a
{kind=link}
Posting Komentar untuk "Sklearn Random Forest Classifier - Why Is Random Forest Better Than Decision Tree?"